프로젝트 개요
텍스트 가이드 기반의 Zero-Shot Composed Image Retrieval 연구입니다. 입력 이미지와 텍스트 쿼리를 결합하여 원하는 특성을 가진 이미지를 검색하는 시스템을 개발했습니다. X:AI 컨퍼런스에서 발표되었으며, 현재 논문 심사 중입니다 (공동 1저자).
Composed Image Retrieval(CIR)은 참조 이미지와 텍스트 쿼리를 결합하여 원하는 특성을 가진 이미지를 검색하는 작업입니다. 예를 들어, "이 이미지에서 배경을 바다로 바꿔줘"와 같은 복합적인 쿼리를 처리할 수 있습니다.
연구 배경 및 동기
기존의 Composed Image Retrieval 방법들은 이미지 전체를 활용하여 쿼리와 매칭하는 방식을 사용했습니다. 그러나 이미지에는 검색과 무관한 배경이나 객체들이 포함되어 있어 노이즈로 작용할 수 있습니다. 특히 텍스트 쿼리가 특정 객체나 영역에 집중하는 경우, 전체 이미지를 사용하는 것은 비효율적입니다.
본 연구는 이미지의 핵심 영역에 집중하여 검색 성능을 향상시키는 방법을 제안했습니다.
주요 기여사항
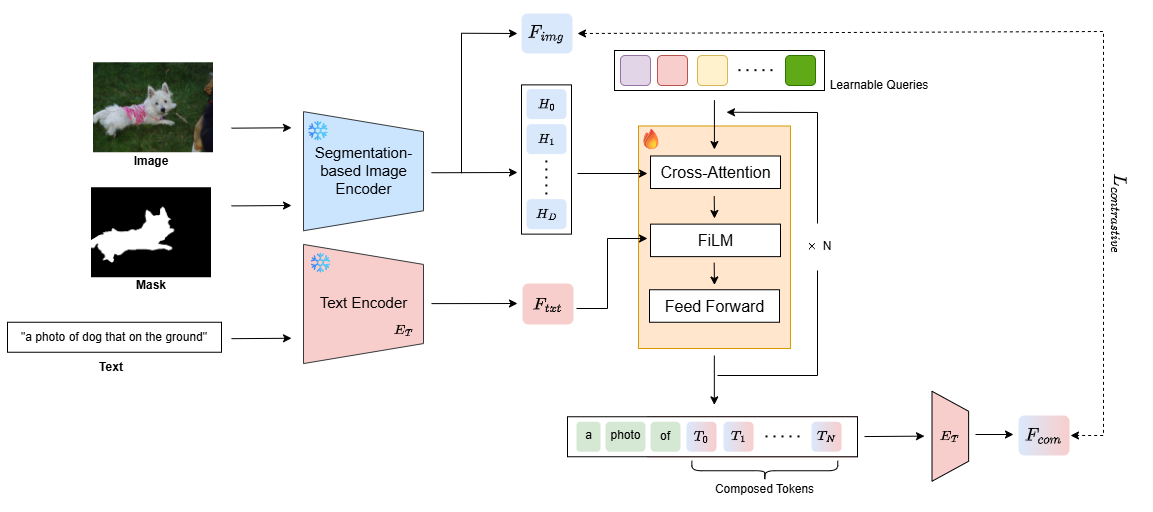
- Segment-Aware Visual Encoding: SAM(Segment Anything Model)을 활용하여 이미지를 세그먼트로 분할하고, 텍스트 쿼리와 관련된 세그먼트만을 선택적으로 활용
- Q-Former 기반 Projection Module: BLIP-2의 Q-Former 구조를 응용하여 Text-Image alignment 향상
- Zero-Shot 성능: 추가 학습 없이 기존 모델을 활용한 Zero-Shot Composed Image Retrieval 달성
- SOTA 성능: COCO Segmentation Benchmark에서 33.2%로 비공식 1위 달성
기술적 방법론
1. Segmentation Module (SAM)
Segment Anything Model(SAM)을 사용하여 입력 이미지를 의미 있는 세그먼트로 분할합니다. 각 세그먼트는 이미지의 특정 객체나 영역을 나타냅니다.
2. Segment Selection
텍스트 쿼리와 각 세그먼트 간의 유사도를 계산하여 관련성 높은 세그먼트만을 선택합니다. 이를 통해 검색과 무관한 배경이나 객체를 제거하고 핵심 영역에 집중할 수 있습니다.
3. Q-Former 기반 Projection
BLIP-2의 Q-Former 구조를 응용하여 텍스트와 이미지 세그먼트 간의 정렬을 개선합니다. Q-Former는 학습 가능한 쿼리 벡터를 사용하여 텍스트와 이미지 간의 교차 어텐션을 수행합니다.
4. Segment-Aware Visual Encoding
선택된 세그먼트들을 통합하여 최종 이미지 표현을 생성합니다. 이 과정에서 각 세그먼트의 중요도를 고려하여 가중치를 부여합니다.
실험 및 결과
COCO Segmentation Benchmark에서 33.2%의 Recall@K를 달성하여 Papers with Code 기준 비공식 1위를 기록했습니다. 제안한 Segment-Aware 방법론이 기존 방법들 대비 유의미한 성능 향상을 보였습니다.
특히 텍스트 쿼리가 특정 객체나 영역에 집중하는 경우, 전체 이미지를 사용하는 기존 방법 대비 큰 성능 향상을 보였습니다.
학술적 성과
본 연구는 X:AI 컨퍼런스에서 발표되었으며, 현재 논문 심사 중입니다 (공동 1저자). Composed Image Retrieval 분야에 Segmentation을 도입한 최초의 연구 중 하나로서 학술적 가치를 인정받고 있습니다.
배운 점
- Composed Image Retrieval의 이론과 실무 적용 방법
- Segment Anything Model(SAM) 활용 경험
- Q-Former 구조의 이해와 응용
- Vision-Language 모델의 Text-Image Alignment 기법
- 학술 논문 작성 및 컨퍼런스 발표 경험